
What is HTTP – Hypertext Transfer Protocol
HTTP (Hypertext Transfer Protocol) is a client-server protocol that fetches HTML texts and connects different networks. When a user makes an HTTP request on the browser, the webserver sends web pages.
What is HTTP protocol?
The Hypertext Transfer Protocol, also known as HTTP, is the protocol that enables hypertext links to load web pages. HTTP is the protocol that serves as the basis for the World Wide Web. The HTTP, is a protocol that operates on top of the lower tiers of the network protocol stack. Its purpose is to facilitate the transfer of data between connected devices. An HTTP transaction typically begins with a client machine sending a request to a server, which is followed by the server sending a response message.
HTTP is a stateless protocol that can be extended with request methods, error codes, and headers. HTTP is a TCP/IP-based protocol used to deliver Web data (HTML files, picture files, query results, etc.). Other ports can be used than TCP 80. It standardizes computer-to-computer communication. HTTP specifies how clients’ request data is produced and provided to servers, and how servers react.
How HTTP works?
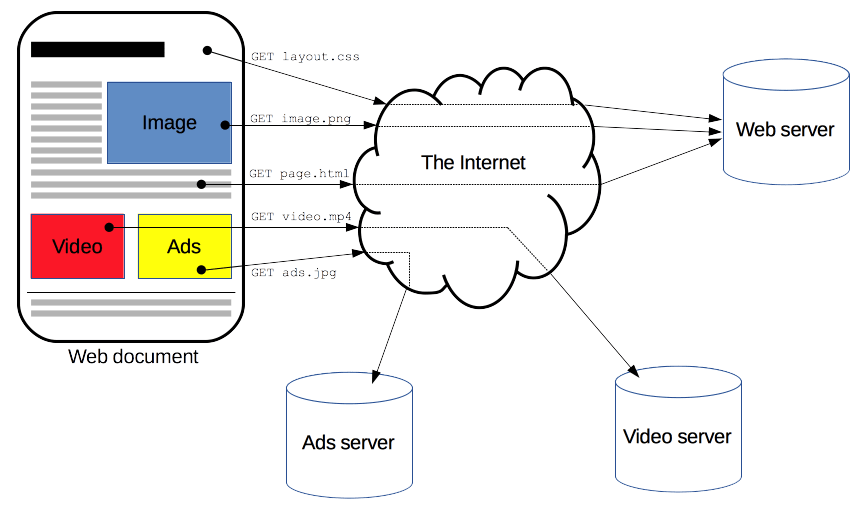
Through HTTP, client devices and servers exchange internet resources. Client devices submit requests to servers for web page resources; servers give responses to clients. Requests and answers share sub-documents including picture, text, and text layout data, which a client web browser pieces together to display the whole web page file.
A web server contains an HTTP daemon, a program that handles HTTP requests. Web browsers transmit HTTP requests to servers. When a browser user “opens” a web file by typing in a URL or clicking on a hypertext link, the browser sends an HTTP request to the IP address indicated by the URL. The destination server’s HTTP daemon accepts the request and returns the requested file(s).
User wants to visit amazon.com. The user types the web address, and the computer sends a “GET” request to the server. This HTTP GET request tells the Amazon server that the user wants the HTML code that structures and styles the login page. Text from the login page is included in the HTML response, while images and videos are requested separately. The more requests made, such as for a website with many photos, the longer it takes the server to respond and the user’s system to load the page.
TCP/IP reduces and transports request/response pairs in tiny packets of binary ones and zeros. These packets are sent across wired, wireless, and fiber optic networks.
Servers and clients utilize ASCII coding to share data. Requests tell the server what the client wants; replies contain code that the client browser converts into a web page.

HTTP vs HTTPS
HTTPS refers to the usage of Secure Sockets Layer (SSL) or Transport Layer Security (TLS) as a sublayer beneath standard HTTP application layers. HTTPS encrypts and decrypts both user HTTP page requests and the pages returned by the web server. Eavesdropping and man-in-the-middle (MitM) attacks are also prevented. Netscape is the creator of HTTPS. Migrating from HTTP to HTTPS is advantageous because it adds an extra degree of security and trust. For more in-depth information, read our complete comparison article here.
HTTP requests and responses
Each time a client and a server communicate with one another, this exchange is referred to as a message. Requests and replies are both possible types of HTTP communications.
HTTP Requests – This occurs when a client device, such as an internet browser, requests information from the server in order to load the webpage. The request gives the server the necessary information to adapt its answer to the client device. Each HTTP request includes encoded data containing information such as:
- The specific version of HTTP followed. The two versions are HTTP and HTTP/2.
- A URL. This is a link to the web resource.
- A type of HTTP method. This specifies the particular action that the request anticipates receiving from the server in its response.
- Request headers in HTTP. This includes information such as the type of browser being used and the information sought from the server. Cookies, which show information previously sent from the server handling the request, can also be included.
- The HTTP body. This is optional information from the request that the server requires, such as user forms (username/password logins, short responses, and file uploads) that are submitted to the website.
HTTP status codes
- 200 OK. This indicates that the request, such as GET or POST, was successful and is being processed.
- 300 Moved Permanently. Permanently relocated. This response code indicates that the URL of the requesting resource has been permanently changed.
- 401 Unauthorized. The client, or user making the request of the server, has not been authenticated.
- 403 Forbidden. The client, or user, making the server request, has not been authenticated.
- 404 Not Found. This is the most commonly encountered error code. It indicates that the URL was not recognized or that the resource at the specified location did not exist.
- 500 Internal Server Error. The server has met a scenario that it is unsure how to handle.
Features
HTTP has three core elements that make it a simple but powerful protocol:
Connectionless: HTTP is a connectionless protocol in which the HTTP client, such as a browser, initiates an HTTP request and then waits for the response. After the server executes the request and returns a response, the client disconnects the connection. So the client and server only know about each other during the current request and answer. Further requests are performed on new connections because the client and server are unfamiliar with each other.
Independent: HTTP is media neutral, which means that it can send any sort of data as long as both the client and the server know how to handle the data content. Both the client and the server must define the content type using the proper MIME-type.
HTTP is stateless: As previously stated, HTTP is connectionless as a result of HTTP being a stateless protocol. Only during the current request are the server and client aware of each other. They both forget about each other after that. Because of the protocol’s design, neither the client nor the browser can save information between requests across web pages.
Components of HTTP protocol
HTTP is a client-server protocol; user-agents send requests (or a proxy on behalf of it). User-agent is usually a Web browser, but it can also be a robot that crawls the Web to maintain a search engine index.
A server handles each request and returns a response. Proxy entities act as gateways or caches between the client and server.
There are routers, modems, and more between a browser and the request server. These are buried in the Web’s network and transport layers. HTTP is an application layer protocol. The underlying layers are critical for diagnosing network problems but unrelated to HTTP.
READ MORE:
- Difference between modem and router
- What Is Good Internet Speed And How Much You Really Need
- Which Types Of Internet Connection Is Good For You

Client – also known as the user-agent
The user-agent refers to any program that performs actions on the user’s behalf. This function is typically carried out by the web browser; however, it may also be carried out by applications that are utilized by engineers and web developers in order to debug the applications that they create.
It is always the browser that will be the one to make the initial request. Never the server is the problem (though some mechanisms have been added over the years to simulate server-initiated messages).
In order for a browser to show a Web page, it must first send an initial request to the server in order to retrieve the HTML document that comprises the page. After that, it performs a parsing operation on this file, during which it makes additional requests that correspond to execution scripts, layout information (CSS) to display, and sub-resources that are present within the page (usually images and videos). After combining all of these resources, the Web page that represents the entire document is shown by the web browser. In later phases, scripts that are performed by the browser have the ability to fetch additional resources, and the browser will update the Web page accordingly.
A hypertext document is referred to as a web page. This indicates that some of the information that is being displayed contains links. These links, when engaged (often by clicking the mouse), cause the user’s user agent to request a new web page. This gives the user the ability to direct their user agent and browse through the web. These instructions are converted by the browser into HTTP requests, and the browser then analyzes the HTTP answers in order to provide the user with an answer that is understandable.
Web server
The client is on one side of the communication channel, and on the other side is the server, which provides the document that the client has requested. A server may appear to be only a single machine virtually; however, it may actually be a collection of servers sharing the load (load balancing), or it may be a complex piece of software interrogating other computers (such as a cache, a database server, or e-commerce servers), completely or partially generating the document on demand. Virtually, a server only appears as a single machine.
There is no requirement that a server be a single physical computer; rather, a single computer can host multiple instances of server software. It is even possible for them to share the same IP address thanks to HTTP/1.1 and the Host header.
Proxies
Multiple computers and equipment, including the user’s browser and the server, are responsible for relaying the HTTP messages. Because of the layered architecture of the Web stack, the majority of them function at the transport, network, or physical levels. As a result, they are invisible at the HTTP layer, despite the fact that they may have a considerable effect on performance. Proxy servers are typically understood to be those that operate at the application layer. These can be transparent, in which case they will forward on the requests that they get without altering them in any way, or they can be non-transparent, in which case they will change the request in some way before forwarding it along to the server. Proxy servers can fulfill a variety of roles, including the following:
- Caching (the cache can be public or private, like the browser cache)
- Filtering (like an antivirus scan or parental controls)
- Load balancing (to allow many servers to serve different requests) (to allow multiple servers to serve different requests)
- Authentication/verification of identity (to control access to different resources)
- Logging (allowing the storage of historical information)
Read More:
Uniform Resource Locator (URL)
A client who wants to view a document on the internet need an address, and to assist document access, HTTP employs the concept of Uniform Resource Locator (URL). The Uniform Resource Locator (URL) is a standard way of specifying any type of internet information. The URL is divided into four sections: method, host computer, port, and path.

-
Method: The protocol used to retrieve the document from a server is referred to as the method. As an example, consider HTTP.
-
Host: The host is the computer that stores the information, and it is given an alias name. Web pages are mostly kept in computers, which are given an alias name that begins with the letters “www.” This field is optional.
-
Port: The URL can also include the server’s port number, however this is an optional field. If a port number is included, it must be placed between the host and the path and separated from the host by a colon.
-
Path: The pathname of the file containing the information. Slashes separate the directories from the subdirectories and files in the path.
Conclusion
HTTP is an easy-to-use protocol that is also capable of being extended. The client-server architecture, in conjunction with the ability to add headers, makes it possible for HTTP to keep pace with the rapidly expanding capabilities of the web.
Despite the fact that HTTP/2 increases complexity by embedding HTTP messages within frames in order to improve performance, the fundamental structure of messages has remained unchanged since HTTP/1.0. The flow of the session is kept simple, which makes it possible to study and troubleshoot it using a straightforward HTTP message monitor.
ad
Comments are closed.