
Amazon Web Services (AWS) offers DynamoDB, a highly scalable and fully managed NoSQL database solution. It provides seamless scalability, automatic data replication, and low-latency performance, making it an excellent solution for applications requiring high availability and quick data access. DynamoDB is built to manage huge workloads and allows developers to store and retrieve structured, semi-structured, and unstructured data. DynamoDB’s pay-as-you-go pricing model and built-in security measures allow enterprises to focus on developing creative apps rather than worrying about database management.
What is DynamoDB?
ad
DynamoDB is a fully-managed NoSQL document database by Amazon that delivers single-digit millisecond performance at any scale. It’s a fully managed, multi-region, multi-master database with built-in security, backup and restores, and in-memory caching for internet-scale applications. DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
DynamoDB stands out as a robust and adaptable alternative among modern database options. DynamoDB, designed by AWS, is a fully managed NoSQL database service that can easily scale to accommodate huge volumes of data. Its adaptable data model supports the storage of a wide range of data types, including JSON documents and key-value pairs. DynamoDB provides consistent, single-digit millisecond latency, allowing applications to provide quick and responsive user experiences. DynamoDB protects sensitive data with built-in encryption, automated backups, and fine-grained access controls. DynamoDB provides the scalability and performance you need to handle your rising data requirements, whether you’re developing web applications, mobile apps, or IoT systems.
More than 100,000 AWS customers have chosen DynamoDB as their key-value and document database for mobile, web, gaming, ad tech, IoT, and other applications that need low-latency data access at any scale. Create a new table for your application and let DynamoDB handle the rest.
DynamoDB can handle more than 10 trillion requests per day and support peaks of more than 20 million requests per second.
ad
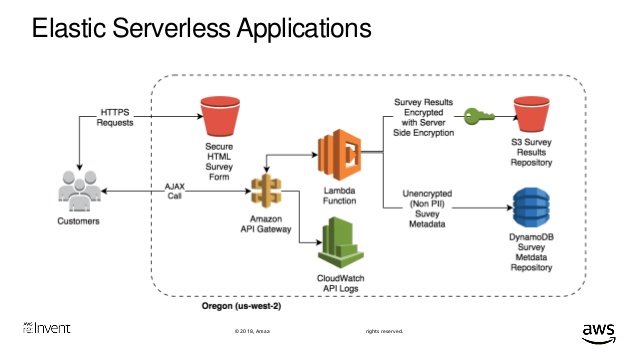
“DynamoDB is a key-value and document database that can support tables of virtually any size with horizontal scaling. This enables DynamoDB to scale to more than 10 trillion requests per day with peaks greater than 20 million requests per second, over petabytes of storage”
DynamoDB Advantages![DynamoDB-Tutorial]()
The two main advantages of DynamoDB are scalability and flexibility. It does not force the use of a particular data source and structure, allowing users to work with virtually anything, but in a uniform way.
Its design also supports a wide range of use from lighter tasks and operations to demanding enterprise functionality. It also allows simple use of multiple languages: Ruby, Java, Python, C#, Erlang, PHP, and Perl.
Limitations
DynamoDB does suffer from certain limitations, however, these limitations do not necessarily create huge problems or hinder solid development.
You can review them from the following points −
- Capacity Unit Sizes − A read capacity unit is a single consistent read per second for items no larger than 4KB. A write capacity unit is a single write per second for items no bigger than 1KB.
- Provisioned Throughput Min/Max − All tables and global secondary indices have a minimum of one read and one write capacity unit. Maximums depend on region. In the US, 40K read and write remains the cap per table (80K per account), and other regions have a cap of 10K per table with a 20K account cap.
- Provisioned Throughput Increase and Decrease − You can increase this as often as needed, but decreases remain limited to no more than four times daily per table.
- Table Size and Quantity Per Account − Table sizes have no limits, but accounts have a 256 table limit unless you request a higher cap.
- Secondary Indexes Per Table − Five local and five global are permitted.
- Projected Secondary Index Attributes Per Table − DynamoDB allows 20 attributes.
- Partition Key Length and Values − Their minimum length sits at 1 byte, and maximum at 2048 bytes, however, DynamoDB places no limit on values.
- Sort Key Length and Values − Its minimum length stands at 1 byte, and maximum at 1024 bytes, with no limit for values unless its table uses a local secondary index.
- Table and Secondary Index Names − Names must conform to a minimum of 3 characters in length, and a maximum of 255. They use the following characters: AZ, a-z, 0-9, “_”, “-”, and “.”.
- Attribute Names − One character remains the minimum, and 64KB the maximum, with exceptions for keys and certain attributes.
- Reserved Words − DynamoDB does not prevent the use of reserved words as names.
- Expression Length − Expression strings have a 4KB limit. Attribute expressions have a 255-byte limit. Substitution variables of expression have a 2MB limit.
This tutorial lets you about the core DynamoDB concepts necessary for creating and deploying a highly-scalable and performance-focused document database.
Tutorial Beneficiary
This tutorial specially designed for IT professionals, students, and management professionals who always wish to have expertise in essential DynamoDB concepts.
After completing this tutorial, you will achieve intermediate expertise in DynamoDB documentation and easily build on your knowledge to solve more challenging problems.
Basic requirement
This tutorial requires a general knowledge of database technology, programming, Java programming languages, and querying languages. It also assumes familiarity with typical database operations in an application.
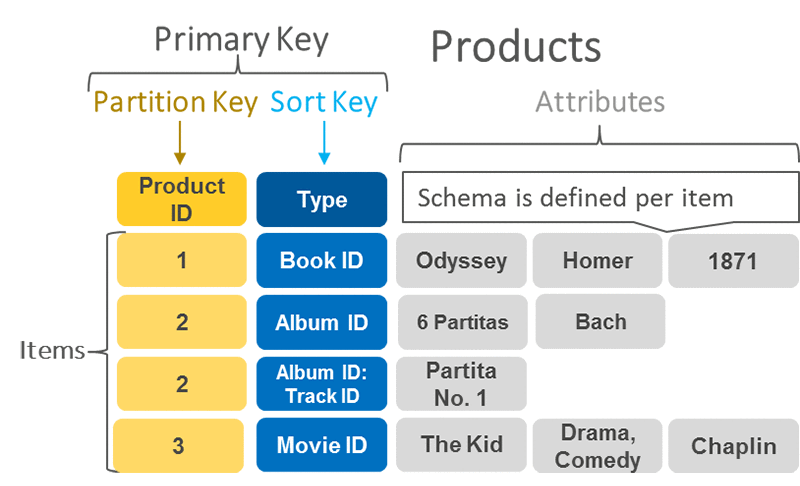
Before using DynamoDB, you must familiarize yourself with its basic components and ecosystem. In the DynamoDB ecosystem, you work with tables, attributes, and items. A table holds sets of items, and items hold sets of attributes. An attribute is a fundamental element of data requiring no further decomposition, i.e., a field.
Primary Key
- Partition key / Hash attribute
- Partition key and sort key / Hash and range attribute
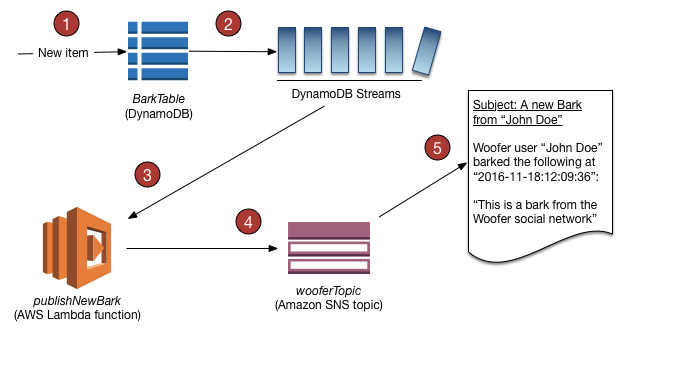
The Primary Keys serve as the means of unique identification for table items, and secondary indexes provide query flexibility. DynamoDB streams record events by modifying the table data.
The Table Creation requires not only setting a name, but also the primary key; which identifies table items. No two items share a key. DynamoDB uses two types of primary keys
- Partition Key − This simple primary key consists of a single attribute referred to as the “partition key.” Internally, DynamoDB uses the key value as input for a hash function to determine storage.
- Partition Key and Sort Key − This key, known as the “Composite Primary Key”, consists of two attributes.DynamoDB applies the first attribute to a hash function, and stores items with the same partition key together; with their order determined by the sort key. Items can share partition keys, but not sort keys.
The Primary Key attributes only allow scalar (single) values; and string, number, or binary data types. The non-key attributes do not have these constraints.
Secondary Indexes![DynamoDB-Secondary-Index]()

These indexes allow you to query table data with an alternate key. Though DynamoDB does not force their use, they optimize querying.
DynamoDB uses two types of secondary indexes −
- Global Secondary Index − This index possesses partition and sort keys, which can differ from table keys.
- Local Secondary Index − This index possesses a partition key identical to the table, however, its sort key differs.
Tables, Items, and Attributes
Tables are used to store data and represent a collection of items. The following figure depicts a table with two items. Each item has a primary key (here: GeekId) and an attribute called “Name”.
Items are similar to rows in other database systems, but in DynamoDB, there is no limit to the number of items that can be stored in one table. The attributes are similar to columns in relational databases, but as DynamoDB is schema-less,
it does not restrict the data type of each attribute nor does it force the definition of all possible attributes beforehand. Beyond the example above, attributes can also be nested, i.e. for example, an attribute address can have sub-attributes named
Street or City. Supported are up to 32 levels of nested attributes.
Streams
An interesting feature of DynamoDB are streams. DynamoDB creates a new record and inserts it into the stream in case one of the following events happens:
- A new item is added to the table.
- An item in the table is updated.
- An item is removed from the table.
The record contains next to metadata about the event like its timestamp also a copy of the item at the moment of the event. In case of updates, it even contains an image before and after the update. If the stream is enabled on table, it can be used to implement triggers. This way you can perform an action in case one of the events above happens. One can imagine to send for example an email if a new order is stored in a table or to order new articles in case it gets out of stock. This feature can also be used to implement data replication or what is known in other database system as materialized views.
Records in a stream are removed automatically after 24 hours.
API![DynamoDB-API]()
The API operations offered by DynamoDB include those of the control plane, data plane (e.g., creation, reading, updating, and deleting), and streams. In control plane operations, you create and manage tables with the following tools −
- CreateTable
- DescribeTable
- ListTables
- UpdateTable
- DeleteTable
In the data plane, you perform CRUD operations with the following tools.
| Create | Read | Update | Delete |
|---|---|---|---|
|
PutItem BatchWriteItem |
GetItem BatchGet Item QueryScan |
UpdateItem |
DeleteItem BatchWriteItem |
The stream operations control table streams. You can review the following stream tools −
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
Provisioned Throughput![Provisioned Throughput]()
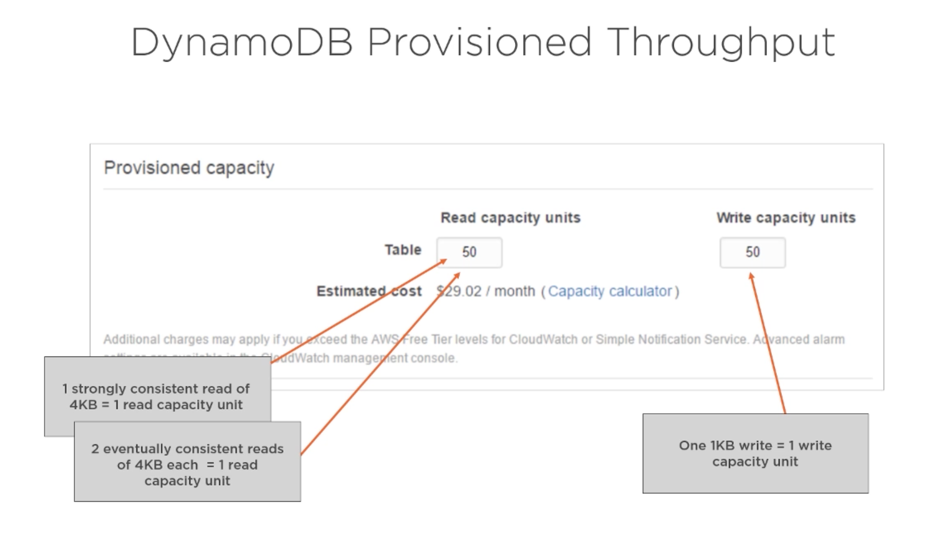
In table creation, you specify provisioned throughput, which reserves resources for reads and writes. You use capacity units to measure and set throughput.
When applications exceed the set throughput, requests fail. The DynamoDB GUI console allows monitoring of set and used throughput for better and dynamic provisioning.
Read Consistency![DynamoDB-Read]()

DynamoDB uses eventually consistent and strongly consistent reads to support dynamic application needs. Eventually, consistent reads do not always deliver current data.
The strongly consistent reads always deliver current data (with the exception of equipment failure or network problems). Eventually, consistent reads serve as the default setting, requiring a set of true in the ConsistentRead parameter to change it.
Partitions![DynamoDB-Partitions]()
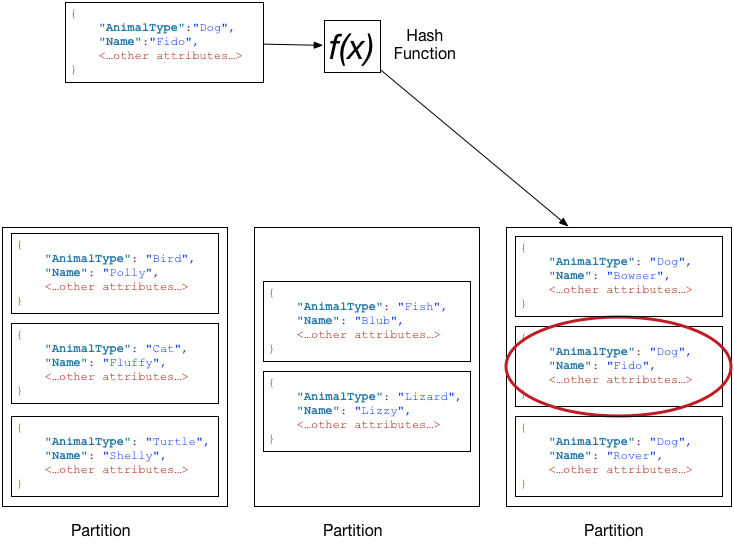
DynamoDB uses partitions for data storage. These storage allocations for tables have SSD backing and automatically replicate across zones. DynamoDB manages all the partition tasks, requiring no user involvement.
In table creation, the table enters the CREATING state, which allocates partitions. When it reaches an ACTIVE state, you can perform operations. The system alters partitions when its capacity reaches the maximum or when you change throughput.
The DynamoDB Environment only consists of using your Amazon Web Services account to access the DynamoDB GUI console, however, you can also perform a local install.
Navigate to the following website − https://aws.amazon.com/dynamodb/
Click the “Get Started with Amazon DynamoDB” button, or the “Create an AWS Account” button if you do not have an Amazon Web Services account. The simple, guided process will inform you of all the related fees and requirements.
After performing all the necessary steps of the process, you will have the access. Simply sign in to the AWS console, and then navigate to the DynamoDB console.
Be sure to delete unused or unnecessary material to avoid associated fees.
Local Install![local install]()
The AWS (Amazon Web Service) provides a version of DynamoDB for local installations. It supports creating applications without the web service or a connection. It also reduces provisioned throughput, data storage, and transfer fees by allowing a local database. This guide assumes a local install.
When ready for deployment, you can make a few small adjustments to your application to convert it to AWS use.
The install file is a .jar executable. It runs in Linux, Unix, Windows, and any other OS with Java support. Download the file by using one of the following links −
- Tarball − http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
- Zip archive − http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
Note − Other repositories offer the file, but not necessarily the latest version. Use the links above for up-to-date install files. Also, ensure you have Java Runtime Engine (JRE) version 6.x or a newer version. DynamoDB cannot run with older versions.
After downloading the appropriate archive, extract its directory (DynamoDBLocal.jar) and place it in the desired location.
You can then start DynamoDB by opening a command prompt, navigating to the directory containing DynamoDBLocal.jar, and entering the following command −
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDb
You can also stop the DynamoDB by closing the command prompt used to start it.
Working Environment
You can use a JavaScript shell, a GUI console, and multiple languages to work with DynamoDB. The languages available include Ruby, Java, Python, C#, Erlang, PHP, and Perl.
In this tutorial, we use Java and GUI console examples for conceptual and code clarity. Install a Java IDE, the AWS SDK for Java, and setup AWS security credentials for the Java SDK in order to utilize Java.
Conversion from Local to Web Service Code
When ready for deployment, you will need to alter your code. The adjustments depend on code language and other factors. The main change merely consists of changing the endpoint from a local point to an AWS region. Other changes require deeper analysis of your application.
A local install differs from the web service in many ways including, but not limited to the following key differences −
- The local install creates tables immediately, but the service takes much longer.
- The local install ignores throughput.
- The deletion occurs immediately in a local install.
- The reads/writes occur quickly in local installs due to the absence of network overhead.
- DynamoDB provides three options for performing operations: a web-based GUI console, a JavaScript shell, and a programming language of your choice.In this tutorial, we will focus on using the GUI console and Java language for clarity and conceptual understanding.
GUI Console
![GUI Console]()
The GUI console or the AWS Management Console for Amazon DynamoDB can be found at the following address − https://console.aws.amazon.com/dynamodb/home
It allows you to perform the following tasks −
- CRUD
- View Table Items
- Perform Table Queries
- Set Alarms for Table Capacity Monitoring
- View Table Metrics in Real-Time
- View Table Alarms

If your DynamoDB account has no tables, on access, it guides you through creating a table. Its main screen offers three shortcuts for performing common operations −
- Create Tables
- Add and Query Tables
- Monitor and Manage Tables
The JavaScript Shell![Javascript Shell]()

DynamoDB includes an interactive JavaScript shell. The shell runs inside a web browser, and the recommended browsers include Firefox and Chrome.
Note − Using other browsers may result in errors.
Access the shell by opening a web browser and entering the following address −http://localhost:8000/shell
Use the shell by entering JavaScript in the left pane, and clicking the “Play” icon button in the top right corner of the left pane, which runs the code. The code results display in the right pane.
DynamoDB and Java
Use Java with DynamoDB by utilizing your Java development environment. Operations confirm to normal Java syntax and structure.
Data types supported by DynamoDB include those specific to attributes, actions, and your coding language of choice.
Attribute Data Types
DynamoDB supports a large set of data types for table attributes. Each data type falls into one of the three following categories −
- Scalar − These types represent a single value, and include number, string, binary, Boolean, and null.
- Document − These types represent a complex structure possessing nested attributes, and include lists and maps.
- Set − These types represent multiple scalars, and include string sets, number sets, and binary sets.
Remember DynamoDB as a schemaless, NoSQL database that does not need attribute or data type definitions when creating a table. It only requires a primary key attribute data types in contrast to RDBMS, which require column data types on table creation.
Scalars
- Numbers − They are limited to 38 digits, and are either positive, negative, or zero.
- String − They are Unicode using UTF-8, with a minimum length of >0 and maximum of 400KB.
- Binary − They store any binary data, e.g., encrypted data, images, and compressed text. DynamoDB views its bytes as unsigned.
- Boolean − They store true or false.
- Null − They represent an unknown or undefined state.
Document
- List − It stores ordered value collections, and uses square ([…]) brackets.
- Map − It stores unordered name-value pair collections, and uses curly ({…}) braces.
Set
Sets must contain elements of the same type whether number, string, or binary. The only limits placed on sets consist of the 400KB item size limit, and each element being unique.
Action Data Types
DynamoDB API holds various data types used by actions. You can review a selection of the following key types −
- AttributeDefinition − It represents key table and index schema.
- Capacity − It represents the quantity of throughput consumed by a table or index.
- CreateGlobalSecondaryIndexAction − It represents a new global secondary index added to a table.
- LocalSecondaryIndex − It represents local secondary index properties.
- ProvisionedThroughput − It represents the provisioned throughput for an index or table.
- PutRequest − It represents PutItem requests.
- TableDescription − It represents table properties.
Supported Java Datatypes
DynamoDB provides support for primitive data types, Set collections, and arbitrary types for Java.
Creating a table generally consists of spawning the table, naming it, establishing its primary key attributes, and setting attribute data types.
Utilize the GUI Console, Java, or another option to perform these tasks.
Create Table using the GUI Console
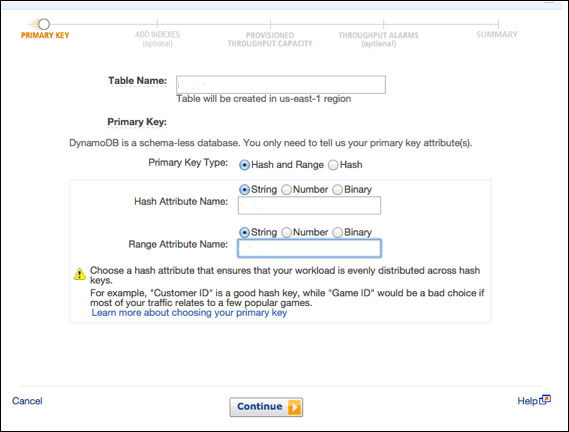
Create a table by accessing the console at https://console.aws.amazon.com/dynamodb. Then choose the “Create Table” option.
Our example generates a table populated with product information, with products of unique attributes identified by an ID number (numeric attribute). In the Create Table screen, enter the table name within the table name field; enter the primary key (ID) within the partition key field, and enter “Number” for the data type.
After entering all the information, select Create.
Create Table using Java
Use Java to create the same table. Its primary key consists of the following two attributes −
- ID − Use a partition key, and the ScalarAttributeType N, meaning number.
- Nomenclature − Use a sort key, and the ScalarAttributeType S, meaning string.
Java uses the createTable method to generate a table; and within the call, table name, primary key attributes, and attribute data types are specified.
You can review the following example −
import java.util.Arrays;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ScalarAttributeType;
public class ProductsCreateTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
String tableName = "Products";
try {
System.out.println("Creating the table, wait...");
Table table = dynamoDB.createTable (tableName,
Arrays.asList (
new KeySchemaElement("ID", KeyType.HASH), // the partition key
// the sort key
new KeySchemaElement("Nomenclature", KeyType.RANGE)
),
Arrays.asList (
new AttributeDefinition("ID", ScalarAttributeType.N),
new AttributeDefinition("Nomenclature", ScalarAttributeType.S)
),
new ProvisionedThroughput(10L, 10L)
);
table.waitForActive();
System.out.println("Table created successfully. Status: " +
table.getDescription().getTableStatus());
} catch (Exception e) {
System.err.println("Cannot create the table: ");
System.err.println(e.getMessage());
}
}
}
In the above example, note the endpoint: .withEndpoint.
It indicates the use of a local install by using the localhost. Also, note the required ProvisionedThroughput parameter, which the local install ignores.
Loading a table generally consists of creating a source file, ensuring the source file conforms to a syntax compatible with DynamoDB, sending the source file to the destination, and then confirming a successful population.
Utilize the GUI console, Java, or another option to perform the task.
Load Table using GUI Console
Load data using a combination of the command line and console. You can load data in multiple ways, some of which are as follows −
- The Console
- The Command Line
- Code and also
- Data Pipeline (a feature discussed later in the tutorial)
However, for speed, this example uses both the shell and console. First, load the source data into the destination with the following syntax −
aws dynamodb batch-write-item -–request-items file://[filename]
For example −
aws dynamodb batch-write-item -–request-items file://MyProductData.json
Verify the success of the operation by accessing the console at −
https://console.aws.amazon.com/dynamodb
Choose Tables from the navigation pane, and select the destination table from the table list.
Select the Items tab to examine the data you used to populate the table. Select Cancel to return to the table list.
Load Table using Java
Employ Java by first creating a source file. Our source file uses JSON format. Each product has two primary key attributes (ID and Nomenclature) and a JSON map (Stat) −
[
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
...
]
You can review the following example −
{
"ID" : 122,
"Nomenclature" : "Particle Blaster 5000",
"Stat" : {
"Manufacturer" : "XYZ Inc.",
"sales" : "1M+",
"quantity" : 500,
"img_src" : "http://www.xyz.com/manuals/particleblaster5000.jpg",
"description" : "A laser cutter used in plastic manufacturing."
}
}
The next step is to place the file in the directory used by your application.
Java primarily uses the putItem and path methods to perform the load.
You can review the following code example for processing a file and loading it −
import java.io.File;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.node.ObjectNode;
public class ProductsLoadData {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
JsonParser parser = new JsonFactory()
.createParser(new File("productinfo.json"));
JsonNode rootNode = new ObjectMapper().readTree(parser);
Iterator<JsonNode> iter = rootNode.iterator();
ObjectNode currentNode;
while (iter.hasNext()) {
currentNode = (ObjectNode) iter.next();
int ID = currentNode.path("ID").asInt();
String Nomenclature = currentNode.path("Nomenclature").asText();
try {
table.putItem(new Item()
.withPrimaryKey("ID", ID, "Nomenclature", Nomenclature)
.withJSON("Stat", currentNode.path("Stat").toString()));
System.out.println("Successful load: " + ID + " " + Nomenclature);
} catch (Exception e) {
System.err.println("Cannot add product: " + ID + " " + Nomenclature);
System.err.println(e.getMessage());
break;
}
}
parser.close();
}
}
Querying a table primarily requires selecting a table, specifying a partition key, and executing the query; with the options of using secondary indexes and performing deeper filtering through scan operations.
Utilize the GUI Console, Java, or another option to perform the task.
Query Table using the GUI Console
Perform some simple queries using the previously created tables. First, open the console at https://console.aws.amazon.com/dynamodb
Choose Tables from the navigation pane and select Reply from the table list. Then select the Items tab to see the loaded data.
Select the data filtering link (“Scan: [Table] Reply”) beneath the Create Itembutton.
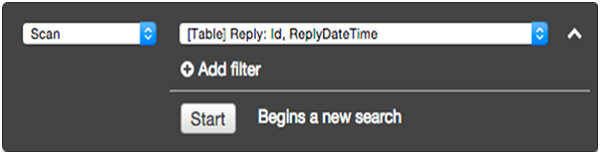
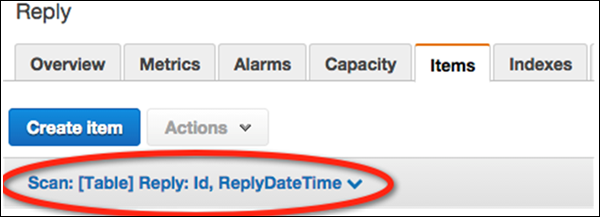 In the filtering screen, select Query for the operation. Enter the appropriate partition key value, and click Start.
In the filtering screen, select Query for the operation. Enter the appropriate partition key value, and click Start.
The Reply table then returns matching items.
Query Table using Java
Use the query method in Java to perform data retrieval operations. It requires specifying the partition key value, with the sort key as optional.
Code a Java query by first creating a querySpec object describing parameters. Then pass the object to the query method. We use the partition key from the previous examples.
You can review the following example −
import java.util.HashMap;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
public class ProductsQuery {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
HashMap<String, String> nameMap = new HashMap<String, String>();
nameMap.put("#ID", "ID");
HashMap<String, Object> valueMap = new HashMap<String, Object>();
valueMap.put(":xxx", 122);
QuerySpec querySpec = new QuerySpec()
.withKeyConditionExpression("#ID = :xxx")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(valueMap);
ItemCollection<QueryOutcome> items = null;
Iterator<Item> iterator = null;
Item item = null;
try {
System.out.println("Product with the ID 122");
items = table.query(querySpec);
iterator = items.iterator();
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.getNumber("ID") + ": "
+ item.getString("Nomenclature"));
}
} catch (Exception e) {
System.err.println("Cannot find products with the ID number 122");
System.err.println(e.getMessage());
}
}
}
Note that the query uses the partition key, however, secondary indexes provide another option for queries. Their flexibility allows querying of non-key attributes, a topic which will be discussed later in this tutorial.
The scan method also supports retrieval operations by gathering all the table data. The optional .withFilterExpression prevents items outside of specified criteria from appearing in results.
Later in this tutorial, we will discuss scanning in detail. Now, take a look at the following example −
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class ProductsScan {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
ScanSpec scanSpec = new ScanSpec()
.withProjectionExpression("#ID, Nomenclature , stat.sales")
.withFilterExpression("#ID between :start_id and :end_id")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(new ValueMap().withNumber(":start_id", 120)
.withNumber(":end_id", 129));
try {
ItemCollection<ScanOutcome> items = table.scan(scanSpec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
Item item = iter.next();
System.out.println(item.toString());
}
} catch (Exception e) {
System.err.println("Cannot perform a table scan:");
System.err.println(e.getMessage());
}
}
}
In this chapter, we will discuss how we can delete a table and also the different ways of deleting a table.
Table deletion is a simple operation requiring little more than the table name. Utilize the GUI console, Java, or any other option to perform this task.
Delete Table using the GUI Console![delete_table_using_the_gui_console]()
Perform a delete operation by first accessing the console at −
https://console.aws.amazon.com/dynamodb.
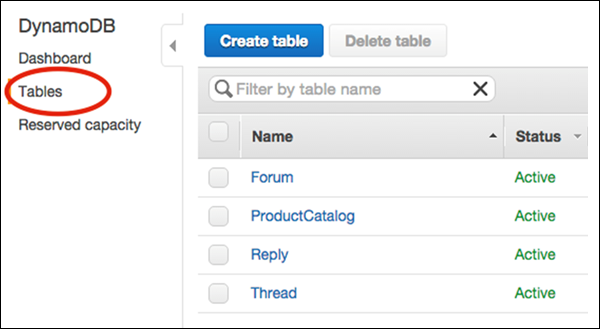
Choose Tables from the navigation pane, and choose the table desired for deletion from the table list as shown in the following screenshot.
Finally, select Delete Table. After choosing Delete Table, a confirmation appears. Your table is then deleted.
Delete Table using Java
Use the delete method to remove a table. An example is given below to explain the concept better.
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ProductsDeleteTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
try {
System.out.println("Performing table delete, wait...");
table.delete();
table.waitForDelete();
System.out.print("Table successfully deleted.");
} catch (Exception e) {
System.err.println("Cannot perform table delete: ");
System.err.println(e.getMessage());
}
}
}
DynamoDB offers a wide set of powerful API tools for table manipulation, data reads, and data modification.
Amazon recommends using AWS SDKs (e.g., the Java SDK) rather than calling low-level APIs. The libraries make interacting with low-level APIs directly unnecessary. The libraries simplify common tasks such as authentication, serialization, and connections.
Manipulate Tables
DynamoDB offers five low-level actions for Table Management −
- CreateTable − This spawns a table and includes throughput set by the user. It requires you to set a primary key, whether composite or simple. It also allows one or multiple secondary indexes.
- ListTables − This provides a list of all tables in the current AWS user’s account and tied to their endpoint.
- UpdateTable − This alters throughput, and global secondary index throughput.
- DescribeTable − This provides table metadata; for example, state, size, and indices.
- DeleteTable − This simply erases the table and its indices.
Read Data
DynamoDB offers four low-level actions for data reading −
- GetItem − It accepts a primary key and returns attributes of the associated item. It permits changes to its default eventually consistent read setting.
- BatchGetItem − It executes several GetItem requests on multiple items through primary keys, with the option of one or multiple tables. Its returns no more than 100 items and must remain under 16MB. It permits eventually consistent and strongly consistent reads.
- Scan − It reads all the table items and produces an eventually consistent result set. You can filter results through conditions. It avoids the use of an index and scans the entire table, so do not use it for queries requiring predictability.
- Query − It returns a single or multiple table items or secondary index items. It uses a specified value for the partition key, and permits the use of comparison operators to narrow scope. It includes support for both types of consistency, and each response obeys a 1MB limit in size.
Modify Data
DynamoDB offers four low-level actions for data modification −
- PutItem − This spawns a new item or replaces existing items. On discovery of identical primary keys, by default, it replaces the item. Conditional operators allow you to work around the default, and only replace items under certain conditions.
- BatchWriteItem − This executes both multiple PutItem and DeleteItem requests, and over several tables. If one request fails, it does not impact the entire operation. Its cap sits at 25 items, and 16MB in size.
- UpdateItem − It changes the existing item attributes, and permits the use of conditional operators to execute updates only under certain conditions.
- DeleteItem − It uses the primary key to erase an item, and also allows the use of conditional operators to specify the conditions for deletion.
Creating an item in DynamoDB consists primarily of item and attribute specification, and the option of specifying conditions. Each item exists as a set of attributes, with each attribute named and assigned a value of a certain type.
Value types include scalar, document, or set. Items carry a 400KB size limit, with the possibility of any amount of attributes capable of fitting within that limit. Name and value sizes (binary and UTF-8 lengths) determine item size. Using short attribute names aids in minimizing item size.
Note − You must specify all primary key attributes, with primary keys only requiring the partition key; and composite keys requiring both the partition and sort key.
Also, remember tables possess no predefined schema. You can store dramatically different datasets in one table.
Backup
To create backups of the data stored in DynamoDB, another Amazon Web Service (AWS) can be used: AWS Data Pipeline. The Data Pipeline service enables you to specify processes that move data between different
AWS services. In the list of supported services we have DynamoDB as well as Amazon S3. This allows us to create a process that exports data from a DynamoDB table into an Amazon S3 bucket at specified intervals.
As a complete description of the AWS Data Pipeline service is out of scopes of this tutorial, we just want to mention that you can open the URL https://console.aws.amazon.com/datapipeline/ in your browser and click on “Create new pipeline”. In the following, you can provide a name and an optional description. For Source you can choose the template andExport DynamoDB table to S3 specify under parameters the name of the table and the S3 output bucket. A more detailed description can be found for example here.
This is an ultimate DynamoDB tutorial
ad
Comments are closed.